We at TaxReco typically deal with large datasets for a variety of customers.
Our Reconciliation Engine has got a suite of comprehensive matching algorithms to match the financial transactions from different data sources.
Typically, this is a 2-stage process.
Stage 1: The users upload their data throw the GUI that includes their expense ledgers, invoice ledgers, tds registers, 26as forms etc (pretty much anything that has a financial transaction in it). This would ingest the data in an optimised format that is more suitable for the Reconciliation.
Stage 2: The users perform the reconciliation by choosing a bunch of parameters through the GUI. This is the stage where the engine performs sophisticated matching for every transaction and produces the output in an easily consumable and reportable format.
At the end of reconciliation, various match scores are generated based on the amount that was matched, no of transactions matched etc.
These scores are kind of used as quality metrics by our customers to know how much transactions are reconciled based on which they can choose the next set of actions suitable for them.
To get the accurate metrics, they must perform the actual reconciliation and wait until the Reconciliation is finished.
Recently, we would like to share an optimisation technique (with a little bit of trade-offs) we have come up with.
The important question we asked ourselves is this:
What if we give our customers a “ball-park” match scores soon after they ingest their data?
This sparked a few other questions too:
How can we give them a score even without applying the sophisticated matching algorithm (which is done by the engine)?
Even if it was achieved somehow, how accurate can this score be?
What’s the extra cost of this (in terms of memory, cpu and the latency)?
The answers we had figured out were the following.
Let’s give the “baseline” score. Now how do we define what baseline is? Well, it means it’s the minimum score below which your actual score is not expected to fall.
One may as what’s the use? It turns out that, if the baseline scores are poor, the customers can straight away work on collecting more good quality data, cleanse the data or even follow it up with their stakeholders who own the data without having to perform the reconciliation. It’s a valuable insight for them given much early in the workflow. Technically, it also avoids the resources from crunching the data intensively and see the bad scores later.
How do we do this without adding much cost?
Enter Probabilistic Data Structures.
By using this type of data structure, we can only safely assume that we have an approximately solution which may or may not be the exact answer but it’s in the right direction. These data structures are proven to use either a fixed or sublinear memory and have constant execution time. As mentioned before, the answers may not be exact and have some probability of error.
There are a few Probabilistic Data Structures that are widely used.
- BloomFilter (with a few variations).
- CountMinSketch
- HyperLogLog
The beauty about the probabilistic data structures are they are very memory efficient and perfect for the situations where one does not need a “perfect” answer.
The approach we had employed in TaxReco is largely inspired by BloomFilter.
For starters, BloomFilter is a data structure to which you can add elements (much like how you’d add to a list or a set).
It’s primary purpose is to check whether an element is present in it or not. Unlike a regular list or a set which gives you a precise binary answer “yes” or a “no”, BloomFilter gives you a “no” or a “may be”.
When it says a “no” it means surely the element is not present. However, when it says a “may be”, then there are chances of false positives. This can be extremely useful in cases where you’re probably okay with false positives and true negatives are very vital.
This link gives a good understanding of how this works.
Coming back to our use case, we use a RoaringBitMap
. RoaringBitMaps are memory efficient long list of Bits which are compressed and optimised to store Sparse data and apply bit operations and set functions on them (eg: And, Or, Contains etc).
I’m going to break this down in simple steps (and simplify it):
Imagine we have 2 data sources A and B.
A could potentially have millions of entries and B could have millions of entries.
Every entry of A when it gets transformed into match keys.
For example:
| TransactionID | Customer | Amount |
| 1 | ABC Ltd | 2500 |
| 2 | XYZ Ltd | 3000 |
| 3 | XYZ Ltd | 2100 |
The MatchKey is a value which could be a concatenation of “TransactionID”, “Customer” and “Amount” in the above data set (it’s much more than that. But let’s keep it simple here).
The MatchKey is then passed to a high-quality Hashing Function. We use Murmur3. This results in a number(say ‘n’). This number is then added to the RoaringBitMap to set the bit at the position n.
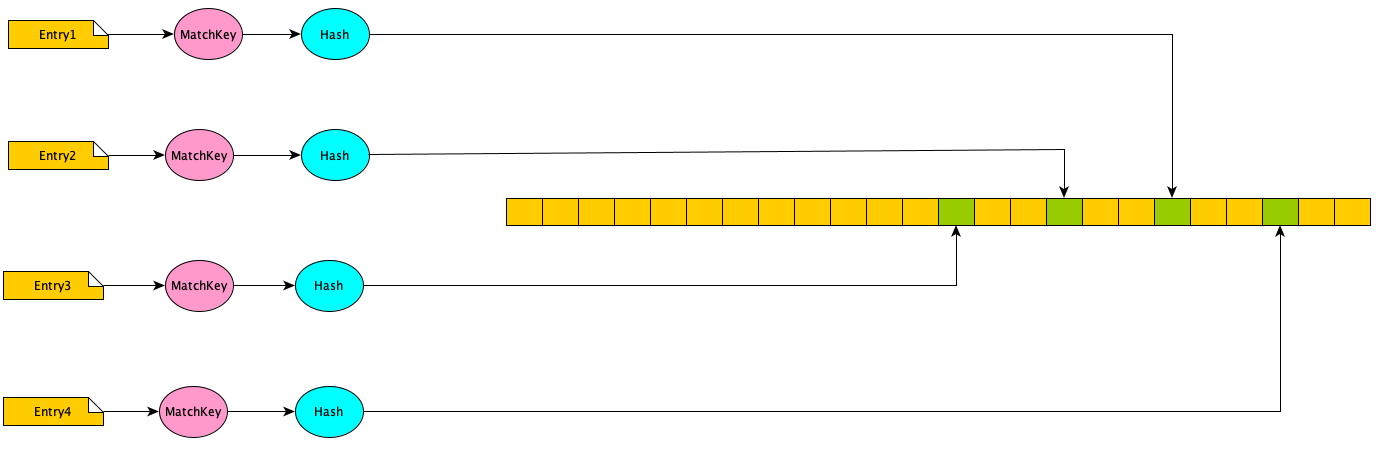
As you see, every entry is hashed and mapped to a specific location which turns the bit on the RoaringBitMap.
Once the Ingest of “A” finished, we persist this RoaringBitMap into the disk – thanks to the serialisation friendly design.
Now when the Ingest of B starts,
The match key is generated for every entry and goes through the same HashFunction to get a numeric value. This numeric value is then checked in the existing RoaringBitMap for the bit value in that position.
If it’s green (meaning it’s set), then this entry is matched with A.
We keep track of how many such entries matched and produce a baseline score. Using a high quality hashing function like Murmur3 produces stunningly accurate results as the probability of hash collision is very low.
The biggest advantage is we give the customers the right direction much earlier than giving them the perfect results much later.
Probabilistic data structures can be a great fit for such use cases at an unimaginably lower memory cost.